Behavioral Models of InfoSec: Prospect Theory
To those in the information security / cyber security industry, it’s an accepted truth that there exists a pernicious incentive structure that overwhelmingly puts the odds in the attacker’s favor. The consistent narrative is that defenders make irrational decisions and focus on the wrong problems while vendors peddle FUD and snake oil that not just fails to bolster the defensive cause, but inflicts ongoing harm.
But, I’ve seen less in the way of seeking to understand defenders’ irrational decision making patterns and why the industry is the way it currently is…and even less about how to fix this toxic feedback loop. So, armed with my modest background in behavioral economics from undergrad, I’ve decided to take a stab at examining the “why” and proposing some ways to twist these incentives in the defense’s favor.
My hope is that this kicks off a series where I examine different theories within behavioral economics against evidence within infosec. The tl;dr background on behavioral econ is that traditional economics views people as rational decision-making machines (i.e. “Homo economicus”) that can perfectly perform cost benefit analyses and choose an objectively optimal outcome.
Behavioral econ, in contrast, recognizes that our brains are wired in a way that has been optimal for evolution, so it measures how people actually behave vs. how they optimally behave. We have quirks in our thinking that result in us making “irrational” decisions, but for understandable reasons.
This post will cover the O.G. theory in behavioral econ, Prospect Theory, as the first of many (potential) theories to help explain some of the dynamics of the infosec market.
Table of Contents:
- What is Prospect Theory?
- Defense vs. Offense
- InfoSec Reference Points
- Empirical Examples from InfoSec
- Incentives in InfoSec
- Fixing Incentives
- Conclusion
What is Prospect Theory?
Prospect Theory is a theory in behavioral econ that helps explain how people make decisions between options that bear certain probabilities and risk. The main thesis in Prospect Theory is that people make decisions by evaluating potential gains and losses through the lens of probability, rather than looking at the final, “objective” outcome. This relies on the decision-maker setting a reference point against which they measure outcomes.
Let’s consider a simple example to get a better sense of what this means in practice, using data from the original paper on Prospect Theory:
Decision #1: A) 100% chance of receiving $3,000 vs. B) 80% chance of receiving $4,000, but a 20% chance of receiving nothing
A’s expected outcome is $3,000 while B’s is $3,200…but 80% of subjects choose option A because it represents a guaranteed gain. Homo Economicus would scoff at these silly people and choose B.
Decision #2: C) 100% chance of losing $3,000 vs. D) 80% chance of losing $4,000, but a 20% chance of losing nothing
C’s expected outcome is losing $3,000 while D’s is losing $3,200. Homo Economicus naturally chooses C, but turns out 92% of people choose D for having the small chance of losing nothing.
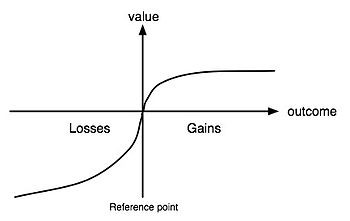 A standard Prospect Theory graph
A standard Prospect Theory graph
People are inconsistent in their choices based on whether decisions result in a loss or gain, as well as how the decisions are framed. There are four key tenets resulting from Prospect Theory that I’ll examine with the lens of infosec:
- Reference dependence: decision makers use a reference point to measure relative gains and losses
- Loss aversion: people really don’t like experiencing losses, and losses hurt 2.25x more than gains feel good
- Non-linear probability weighting: people tend to overweight small probabilities and underweight big ones, and they also like certainty
- Diminishing sensitivity: the farther an outcome is above or below the reference point, the less its marginal effect
Defense vs. Offense
 Get ready for more terrible cyber art throughout the post
Get ready for more terrible cyber art throughout the post
Through the lens of Prospect Theory, my own theory is that defenders operate in the “realm of losses” while attackers operate in the “realm of gains.” As shown above, people in the domain of losses tend to be more risk-seeking, while those in the gain domain tend to be risk averse. In fact, losses felt by those in the gain domain are overvalued by 3:1 relative to those in the loss domain. The further defenders get away from their reference point, the more they’ll opt for small probabilities of a big leap closer to it instead of more certain, incremental improvements — that is, become more risk-seeking and pay more attention to potential payoffs rather than probabilistic outcomes.
Defenders take awhile to readjust their point of reference to match the status quo, which can really screw up their decision-making process; if potential outcomes are computed relative to the reference point, an outdated reference point will reinforce risky decision-making as defenders keep trying to jump back up to it. Attackers, on the other hand, will quickly update their reference point to the status quo. Given their predilection towards risk aversion and emphasis on weighing the probability of different outcomes, attackers need a technical and informational advantage to feel confident in their decision.
InfoSec Reference Points
 Look, they’re pointing
Look, they’re pointing
In order to figure out the behavioral predilections of defenders and attackers within the infosec arena, we need to determine the reference points that guide their behavior. My theory on infosec reference points is the following:
- Defenders’ reference point is a security posture in which they can only withstand set Z of attacks, do not experience any materially significant breaches (e.g. those requiring disclosure), and spend $X on products to meet minimum compliance standards: Domain of Losses
- Attackers’ reference point is successfully compromising a target for $X cost without being caught before achieving their goal with value $Y: Domain of Gains
Therefore, we have the following conclusions on losses and gains for each party:
- Defenders feel a loss when they are breached with set Z of attacks, experience a significant breach, or spend more on security products than the minimum needed to meet compliance requirements. The gain from spending less than $X to meet compliance standards is realistically trivial. The non-trivial gain is from successfully stopping attacks that are not included in set Z (i.e. those they assume they can’t withstand); for example, an advanced remote code execution exploit involving a sandbox escape, kernel privilege escalation and a payload that disables endpoint protection products.
- Attackers feel a loss whenever they are caught or when their cost of $X is greater than their outcome of $Y, and feel a gain if they either spend less than $X on an attack or have a greater outcome than $Y. Note, a gain here would include exploits that work across multiple platforms or malware that can be repackaged easily, since it’s reducing the marginal cost of $X for crafting each attack and is thus a superior use of the attacker’s development time. For example, an exploit for a design flaw, architectural weakness, or logic-based vulnerability is usually cross-platform, reliable (vs. memory corruption) and very likely will take longer to fix — all of which means it has a larger payoff for the time invested in its development.
Empirical Examples from InfoSec
 ThreatButt: the #1 must-have, best-of-breed, military-grade enterprise cyber defense-in-derpth platform
ThreatButt: the #1 must-have, best-of-breed, military-grade enterprise cyber defense-in-derpth platform
It’s important to highlight some examples of “irrational” behavior within infosec as a frame of reference for general theory, specifically focusing on differences in adoption (and hype) of various defensive security products. Irrational can be a subjective term, so I mean it in both the “counter to one’s own benefit” way and the “most outside observers think this is illogical” way.
Let’s start with EMET, Microsoft’s Enhanced Mitigation Experience Toolkit, a free tool that helps prevent software exploitation on Windows. Installing it and configuring commonly used applications with ASLR, DEP and other countermeasures significantly increases the difficulty of successfully compromising an application. While there are no official statistics, it’s widely accepted that EMET adoption rates are very low, despite it being free and well-tested.
In the years following the initial release of EMET, some of its features and functionality slowly crept into mainstream operating system releases, where their efficacy forced attackers to move to Office macros — a decision that involved attackers accepting the risk of savvy users who wouldn’t enable the macros rather than investing time in developing and retooling exploits to work in a post-EMET world. This is a good example of attacker risk aversion; they prefer to go for the fluffier target that requires less fancy exploitation, but still has a wide impact. Similarly, Java historically made a fantastic target for attackers because of its uniformity. Attackers could simply write their attack once and reuse it, which made it appealing from a ROI perspective.
Two-factor authentication (2FA) is another example of a solution that isn’t “sexy” per se but should receive greater hype relative to its defensive impact. It’s a low cost solution that’s easily deployed (particularly relative to most security products), and meaningfully bolsters account security beyond just passwords. Yet, it’s taken 7 years to get to the point where it is being widely acknowledged as a standard tool to have in the security arsenal — and adoption still isn’t ubiquitous among the largest consumer-facing firms, despite how inexpensive and simple it is.
Just take a look at the list of the firms who do and don’t have 2FA to see how many notable companies don’t have it yet. And, among the financial services firms who don’t, it’s a somewhat solid bet that they do have a FireEye box, Bromium or some other anti-APT tech which is vastly more expensive and helps against much lower-probability attacks.
The rise of ransomware and how little has been done to preemptively stop its growth and potency is also perplexing. According to PhishMe, 93% of all phishing emails now contain ransomware. McAfee says there were nearly 1.2 million new ransomware kits in Q1 2016 alone, the total nearing 6 million. It’s an unsophisticated attack that can easily be conducted by the 13 year old in Romania using basic malware kits, presenting a high ROI to the attacker. But given the prevalence and impact of ransomware, it seems irrational that companies are not doing more to protect against it.
Part of this is cleverness by the attacker in making the ransom’s cost low enough to not cause their targets to take drastic measures, but high enough that over a big enough target base, it results in lots of cash against a one-time upfront cost they can amortize over the lifetime of the attack. However, it’s more likely an element of defense being slow to update their reference points; companies could still be adopting relatively low-cost solutions and strategies to better defend themselves against ransomware, such as email protection, filesystem canaries, or even just a better backup process. All three of those solutions would benefit any organization beyond just becoming more resilient against ransomware, and yet they remain some of the most “boring,” underlooked categories.
Canaries in general, in fact, are a smart idea. Yet at only 4-figures per box, they are criminally under-adopted relative to 6-figure anti-APT boxes. It’s pretty straightforward: set up something that looks like a juicy target for an attacker, and get alerted when there’s suspicious activity. It helps give you early breach detection, inform your threat model and better understand attacker behaviors, all for a reasonable price. But adoption is very far from ubiquitous. Unfortunately it doesn’t have hand-wavy technology that “stops” advanced attacks — it comes across more like a mouse trap with cheese than a sexy elaborate laser tripwire maze.
As a final example, application whitelisting is a highly effective, albeit mundane technology. Plenty of organizations are still being compromised with new executables running, something easily thwarted by whitelisting. However, there’s a lower probability of catching an “elite” attack, given it’s likely to exploit an application directly. Critics will say that whitelisting reduces flexibility and bears a non-trivial amount of upfront setup, which is fair until you consider how difficult “sexy” tech, commonly using kernel-level modules, is to implement.
Incentives in InfoSec
 Helps determine the direction of a cyber object from the observer
Helps determine the direction of a cyber object from the observer
With the above as a reference, I’m going to walk through each of the four key tenets and examine their likely implications in infosec, and how they can explain the “irrational” decision making that many bemoan.
Reference Dependence
While it’s (mostly) simple accounting for defenders to know how much is spent on compliance, it’s a lot harder to know your organization’s security posture. Attackers can rely on (mostly) simple accounting to tally their cost and probably guesstimate the value of a successful attack, particularly if it’s selling personal data for $X per user vs. a nation state calculating how much crippling an enemy’s nuclear facility is worth to national security. Defenders, in contrast, can’t tally their costs as they go.
Figuring out your security posture is complicated for a few reasons. First, there are no sufficient industry benchmarks for security health against which organizations can compare themselves. Second, it’s highly unlikely that organizations will have full situational awareness to know which attacks are working against them and which they’re successfully thwarting. Third, defenders aren’t always sure what the “spoils of war” are, i.e. what value an attacker gains from hacking them, from customer data, intellectual property even to something like carbon credits. When it’s difficult to know what’s at risk, it’s difficult to weigh risk.
And, updating the reference point is a slow process for defenders. If their reference point is their perception of their security posture from 2014, it’s now outdated by two years at the minimum, during which attackers assuredly developed new techniques. Even once the reference point is updated to the status quo, the uncertainty in measuring organizational security risk and health means the new reference point will be equally as fuzzy. Just think about the ransomware example; if the reference point were based on today’s most probable threats, adopting technologies to prevent it should be a top budget priority.
Attackers, however, are quickly updating their reference points and evolving their methods based on the true status quo rather than their prior perception. Because the reference point serves as the foundation for decision making under prospect theory, the fact that attackers have more timely and accurate reference points gives them a decisive advantage at stage 1 over defenders.
Loss Aversion
We know that losses hurt 2.25x more than gains, and that attackers weigh losses 3x as much as defenders; to be a bit simplistic, the attacker’s “exchange rate” for gains and losses is therefore 1: 6.75. Defenders “just” need to make sure that for each additional dollar attackers spend towards breaching them, they’re getting less than $6.75 in additional value (I’ll discuss how defenders can do so in the last section).
As mentioned in the EMET example, attackers were probably inclined to switch to less arduous targets once it was released just based on the assumption that organizations would have adopted it, even though there wasn’t yet evidence of adoption. As a free tool, adopting it couldn’t present an easier, cost-effective opportunity for defenders to play into attacker’s loss aversion.
Non-linear Probability Weighting
Both sides overweight small probabilities and underweight large ones. Defenders are predisposed towards following small probabilities of a better outcome (risk-seeking) while attackers will care more about certainty and shun options that have smaller probabilities of worse outcomes (risk-averse).
To feel confident in their abilities to pwn their target, attackers need a strong reference point and the ability to calculate the probabilities of different outcomes. The more information the attacker has about the target, the better they can predict probability, and the greater their technical abilities, the better they can minimize the probability of being caught. Consequently, playing with attackers’ sense of certainty is another tactic defenders can use.
In defensive decision making, it’s crucial to understand the impact and probability of an attack on your organization. There’s a reason why there’s been a collection of attempts to come up with a framework for information security risk-weighting — it’s vital, but an arguably unattainable goal. The variables are prohibitively multifarious, from the company’s industry, technology stack, business model, brand power, etc. to attacker motives, current malware landscape, or even geopolitical statuses.
It’s safe to assume that it’s an impossible task to enumerate all attacks and calculate each of their probabilities and impacts. Industry data is pragmatic since it provides a reasonable reflection on what attacks are most likely. There’s also some data to provide historical precedents on impacts; for example, there’s minimal impact to stock prices, but potentially longer-term impact to sales that ends up affecting stock prices (like in Target’s case). This still leaves the defender left to determine whether they’re robust enough to withstand these different types of attacks .
Now, remember that loss domain-ers will overweight small probabilities and my hypothesis that the only “gain” a defender can really have is stopping attacks that they did not think they could. This can easily support why information security is saturated with products that stop APT or “advanced” attacks, while companies are still getting popped with “basic” methods like phishing, simplistic web app vulnerabilities and outdated, repackaged malware. The tools I mentioned above, such as 2FA, canaries and whitelisting help stop the large-probability, quotidian attacks and thus don’t present an opportunity for a “gain.”
Such a limited potential for a gain facilitates greater emotional basis for action as well, such as Clausewitz’s “passionate hatred for the enemy.” It’s no wonder, then, that attribution is so popular while being functionally useless — at least defenders can have some respite that the culprits were found. But I believe it’s more than that; giving a “face” to the attackers provides a greater sense of certainty, however false that feeling might be. And if I’m generous, nicely bound reports on threat group “[clever noun describing the target group] + [noun of Chinese-associated thing]” detailing TTPs might actually help defenders improve their probability weighting of what attacks they’re likely to incur.
Diminishing Sensitivity
As defenders experience losses, they experience less “pain” for each additional instance. A big, acutely painful breach will more likely lead to action (of the risk-seeking kind) rather than death by a thousand paper cuts, which fully plays into diminishing sensitivity — each time a defender is hacked via a “stupid” bug, they’ll care less and less, so they’ll be less inclined to adopt security products that stop the repeated, lesser attacks (such as 2FA or canaries).
Another issue is that the outcome for defenders is often all or nothing. For example, if an attacker bypasses ASLR, the yield is 100% of the app; there’s no gray area where only part of the app is compromised, meaning from the defender’s point of view, it’s either a total loss or no loss. By this I mean, if an attacker has a 1/10 chance of guessing an address layout, the app is not 90% protected, and if an attacker guesses correctly, the app is 100% compromised. Thus, the impact of this 100% loss is the initial hit, and any subsequent hits don’t feel nearly as severe in comparison.
This disparity between losses is why incident response is such a lucrative business; when defenders are violently thrust deeper into the loss domain, they’re much more willing to spend whatever money necessary to get closer to their reference point again. This takes the form of expensive services or products that the IR providers say will help avoid this big, nasty pain they’re feeling…although this dynamic is often decried as predatory.
On the attacker side, achieving increasingly awe-inspiring levels of leetness loses its splendor after awhile; that is, there’s less motivation to strive for either an extra level of cost reduction or getting more value out of the attack. However, the initial gain leap can still be appealing, and is where I’d argue a lot of innovation happens…it’s just that there isn’t much incentive to continue to innovate.
This explains a few observations. First, that you commonly see the same attack being repackaged rather than completely new methods being used during a campaign. Second, wildly innovative, “great leap forward” vulnerability research is more common once some sort of new protection is developed and deployed (like ROP being used to work around a non-executable stack/heap), and less common when the status quo attacks can do just fine (like users plugging in shiny USBs they find in the parking lot).
What this also means, combined with attackers being more risk averse, is that reaching the next gain level will decreasingly justify the risk tradeoff. This is yet another benefit to the defense, since it can help deter ongoing campaigns even after an initial compromise — if you can up the cost of persistence, then developing tools for retaining system access on the target system will feel too risky relative to the lower gain payoff.
Fixing Incentives

Now that I’ve tried explaining the why, it’s time to discuss how the balance of decision-making power can be shifted in favor of defense and some examples of tech that makes more sense to adopt. Clearly, defense is naturally predisposed to misjudging their real threat model, misallocating resources and miscalculating strategies, resulting in our current industry dystopia of a comically privileged offense, FUD marketing tactics, focus on thwarting sexier “advanced” attacks and a noxious romance with attribution.
Understanding you have a problem, what the problem is, and why you keep having it is step one. I’m not alone in using knowledge of behavioral econ to counter my human instincts towards suboptimal behavior (e.g. instant gratification monkey). So, I fully believe that defenders can leverage the knowledge of their weaknesses to correct their missteps and start leveraging their adversaries’ weaknesses against them.
If you’ve spoken to anyone in infosec with offensive experience, they’ll agree that “raising the cost of attack” is one of the most effective means of deterrence. I think re-framing it as “raising the stakes of attack” is more descriptive than cost, since it includes the notion of risk. The fact that attackers only care about their own outcome relative to the reference point, are extremely loss averse, prioritize certainty over a more valuable outcome and get less benefit out of successive gains all supports the idea of raising the stakes.
Defenders should prioritize efficiency when raising the stakes. Rather than focusing on less probable attacks, they should think about the commonalities between the technical and informational advantages that the spectrum of attackers possess. For example, a platform like Drawbridge Networks lets you detect and control lateral movement in an internal network, which could limit an attack’s impact in both more advanced attacks and common malware. Defenders often believe that cyber security products focused on countering “advanced” threats also counter more basic attacks, but that’s not always the case. It’s far simpler to raise the level of the lowest common denominator than try to stop each type of “sophisticated” method.
Eroding the informational advantage is the wisest move, since tackling the technical advantage is more of a cat-and-mouse game. “Silent” monitoring tech that gives visibility without informing the attacker can give defense the ability to respond quickly without the attacker realizing that they’ve been caught, so defenders can watch the attacker’s methods and gain valuable threat intelligence (the real kind). In contrast, technologies that use blocking are giving data to attackers that they can use to craft a better attack.
An effective technique that’s gaining some popularity is ensuring that the organization’s infrastructure isn’t static; attackers will have a substantially more difficult time attacking something that is constantly changing. Even more simplistically, setting up honey pots and other types of deception, like Thinkst’s Canary, can serve to foster uncertainty in the attacker as well as give defense the heads up that something nefarious is happening.
Defenders should also reduce their adversaries’ potential payoff in conjunction with raising the stakes. Having strict access control rules and a more segmented network means that a compromise of an individual machine doesn’t have much value, and attackers will have to expend more resources to get a bigger payoff. For example, deploying Duo Sec’s 2FA to end users reduces the value of their credentials by adding an extra hoop through which attackers must jump to illicitly access accounts.
But to counter their own weaknesses, defenders should take a data-driven approach — although data can have its flaws, it helps provide rational evidence of what the reference point should be. Having an ongoing picture of the “true” threat model may also encourage defenders to update their reference point more quickly, though it will still require some introspection to be aware of their bias towards being slow to change their views. One tech solution with this approach is Signal Sciences, which uses a data-driven approach to web app security by providing a continuously updated reference point of security posture in that area.
There also needs to be a better understanding in defense of how they define a loss. As I theorized earlier, right now it’s mostly “being breached,” and that may indeed have an immediate impact on the security practitioner’s job security. However, it’s probable that a nation state attacker will breach a company, exfiltrate some data for espionage purposes, and there will be no real effects felt by the company (particularly short-term). Enhancing the equation of probability * outcome with an improved understanding of the real impact different types of attackers has on the organization would meaningfully improve prioritization of what solutions to adopt from lens of what is bad from the organizational point of view vs. what is bad from an “objective” security point of view.
Conclusion
 Real hackers use this leet virtual reality module for their attacks
Real hackers use this leet virtual reality module for their attacks
I really believe understanding the motivations behind this “irrational” defensive behavior is empowering. While even I tend to veer towards hyperbole when describing offense’s advantages, the offense isn’t invisible nor is their decision-making flawless, and I think Prospect Theory helps identify those vulnerabilities — so now the challenge is for defense to start exploiting them.
My hope is that rather than telling infosec defenders that they’re being stupid or irrational or that they’re totally crappy at their jobs, the industry can take a more empathetic approach and suggest strategies towards ameliorating counterproductive incentives. I don’t think that will eradicate FUD marketing tactics or snake oil products, but it probably can give solutions that actually help a fighting chance to make a difference.
In conclusion, let’s try to be more of a community and practice some collective mindfulness, and just maybe we can start fixing things.